「Turbo Graphics」(安齋利洋・伊吹龍著;1987年)にはもう少し複雑なkameの再帰描画の例が載っている。プログラムをなぞってPythonで書くと以下のようになる:
#coding: utf-8
import turtle
def sugata( center, size):
for i in range(6):
painter = center.clone()
painter.fd(size)
painter.rt(120)
painter.fd(size)
center.rt(60)
def kame( position, size):
sugata( position, size)
if size > 10:
position.fd(size/2)
kame(position, size/2)
position.bk(size)
kame(position, size/2)
if __name__ == '__main__':
turtle.clearscreen()
position = turtle.Turtle()
position.ht()
position.lt(90)
kame( position, 200)
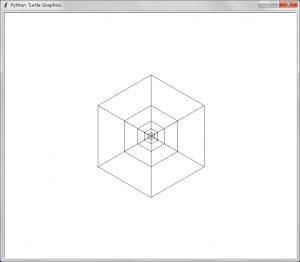
描画は以下のようになる:
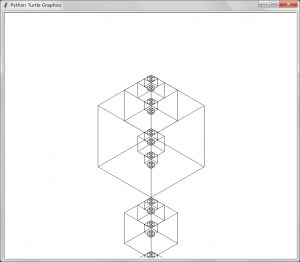
ご覧のように再帰の描画がずれたものになっている。
このずれの原因として考えられるものはオブジェクトを関数に渡す仕様がTurboPascalとPythonとで異なることにあるように思われた。そこで
def kame( positionT, size):
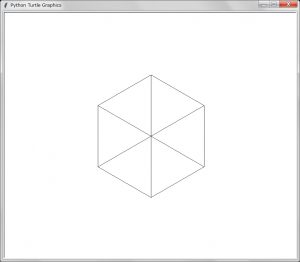
position = positionT.clone()として関数の中で実引数が影響を受けないようにした。結果の描画は以下のようになる:
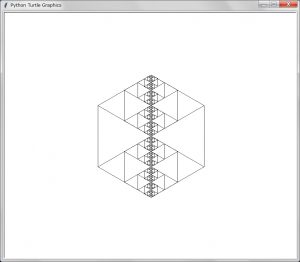
これで期待した通りになったが、描画のアルゴリズムを変えてクローンを使わないことにしたい。