
今朝の地方紙の記事のタイトルである。
もみ殻が紫色をしたブータンの稲の写真が印象的な記事である。冷害に強い遺伝子を持った種子を保存する。またこの稲が冷害に耐えられる調べる「耐冷性検定圃場」での実験の写真もある。水温は18.5~19度と冷たい。
この試験場ではササニシキ、ひとめぼれ、だて正夢の宮城県産の稲品種の開発に関わってきた実績がある。
今朝の地方紙の記事のタイトルである。
もみ殻が紫色をしたブータンの稲の写真が印象的な記事である。冷害に強い遺伝子を持った種子を保存する。またこの稲が冷害に耐えられる調べる「耐冷性検定圃場」での実験の写真もある。水温は18.5~19度と冷たい。
この試験場ではササニシキ、ひとめぼれ、だて正夢の宮城県産の稲品種の開発に関わってきた実績がある。
先のkameの複雑な再帰描画をクローンを使わないで行うことを考える。まず問題の所在を明確にするためにプログラムにデバッグ用のprint文を追加した。プログラムの一部を載せる(再帰の深さは浅くしてある)。
def kame( position, size):
space = ' '*4*(int(200/size)-1)
print(space, 'draw kame',position.ycor(), size)
sugata( position, size)
if size > 75:
position.fd(size/2)
kame(position, size/2)
position.bk(size)
kame(position, size/2)
print(space, 'returning', position.ycor(), size)
この出力は以下のようになる:
draw kame 0.0 200
draw kame 100.0 100.0
draw kame 150.0 50.0
returning 150.0 50.0
draw kame 50.0 50.0
returning 50.0 50.0
returning 50.0 100.0
draw kame -150.0 100.0
draw kame -100.0 50.0
returning -100.0 50.0
draw kame -200.0 50.0
returning -200.0 50.0
returning -200.0 100.0
returning -200.0 200draw kame 100に対応する(再帰のレベルが同じ)描画がdraw kame -150となっておりこれがずれの原因になる。
そこで関数kameに渡したオブジェクトpositionの属性がこのkame関数のなかで最終的に変化がなかったようにダミーの動きをいれる。プログラムは以下のようになる。
#coding: utf-8
import turtle
def sugata( center, size):
for i in range(6):
painter = center.clone()
painter.fd(size)
painter.rt(120)
painter.fd(size)
center.rt(60)
def kame( position, size):
#space = ' '*4*(int(200/size)-1)
#print(space, 'draw kame',position.ycor(), size)
sugata( position, size)
if size > 10:
position.fd(size/2)
kame(position, size/2)
position.bk(size)
kame(position, size/2)
position.fd(size/2) #ダミーの動き
#print(space, 'returning', position.ycor(), size)
if __name__ == '__main__':
turtle.clearscreen()
position = turtle.Turtle()
position.ht()
position.lt(90)
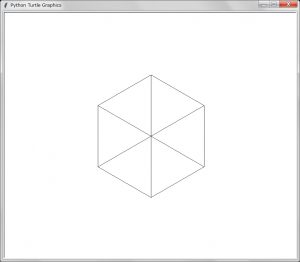
kame( position, 200)【結果の描画」
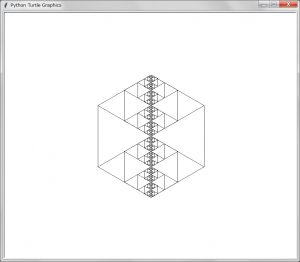
期待した通りの結果が得られた。
「Turbo Graphics」(安齋利洋・伊吹龍著;1987年)にはもう少し複雑なkameの再帰描画の例が載っている。プログラムをなぞってPythonで書くと以下のようになる:
#coding: utf-8
import turtle
def sugata( center, size):
for i in range(6):
painter = center.clone()
painter.fd(size)
painter.rt(120)
painter.fd(size)
center.rt(60)
def kame( position, size):
sugata( position, size)
if size > 10:
position.fd(size/2)
kame(position, size/2)
position.bk(size)
kame(position, size/2)
if __name__ == '__main__':
turtle.clearscreen()
position = turtle.Turtle()
position.ht()
position.lt(90)
kame( position, 200)
描画は以下のようになる:
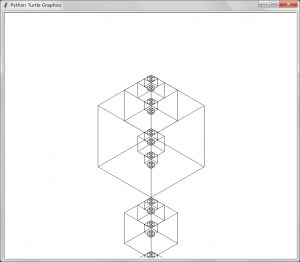
ご覧のように再帰の描画がずれたものになっている。
このずれの原因として考えられるものはオブジェクトを関数に渡す仕様がTurboPascalとPythonとで異なることにあるように思われた。そこで
def kame( positionT, size):
position = positionT.clone()として関数の中で実引数が影響を受けないようにした。結果の描画は以下のようになる:
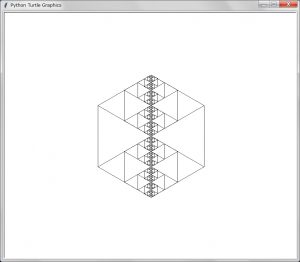
これで期待した通りになったが、描画のアルゴリズムを変えてクローンを使わないことにしたい。
Pythonのタートル・グラフィックス(1)で採り上げたKameの単純な再帰プログラムを考える。プログラムは以下のようなものである:
#coding: utf-8
import turtle
def sugata( center, size):
for i in range(6):
painter = center.clone()
painter.fd(size)
painter.rt(120)
painter.fd(size)
center.rt(60)
def kame( position, size):
sugata( position, size)
if size > 10:
kame(position, size/2)
if __name__ == '__main__':
turtle.clearscreen()
position = turtle.Turtle()
position.ht()
position.lt(90)
kame( position, 200)
実行結果の描画
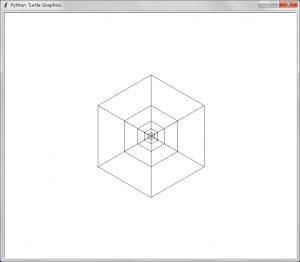
期待した結果である。
稲の刈り入れの季節である。今では刈り入れは稲の根元から刈り取る「根刈」である。
「栽培植物と農耕の起源」(中尾佐助著)の中でこの「根刈」と対比して「穂刈」を紹介している。原始的な農業では「穂刈」が一般的である。それは穂の脱落性(触れると落ちる)と出穂期(いっせいに穂がでるかどうか)の性質が、脱落性があり、出穂期が揃っていないからである。脱落性がなくなり出穂期がいっせいになるような改良がされると収穫方法も「穂刈」から「根刈」に移行する。
日本でも米の収穫は奈良時代までは「穂刈」で、平安時代になると「根刈」に移行したと言われている。
今日の新聞の記事のタイトルである。
ノルウェー政府は来年3月開催予定の核兵器禁止条約締約国会議にオブザーバー参加をすることを明らかにした。北大西洋条約機構(NATO)の加盟国が会議への参加を表明するのは初めての由。
同国内では政府が条約に署名するよう求める声が高まっている。2019年の調査では有権者の78%が政府は条約に署名すべきたと回答。
ノルウェーでは政権交代が実現。中道左派・労働党と中央党の少数連立政権が誕生。この政府による参加表明である。
LibreLogoに関するブログを書いていたらPythonのタートル・グラフィックスことが気になった。
書架を見たら「Turbo Graphics」(安齋利洋・伊吹龍著;1987年)という昔使った本が目についた。これはTurbo Pascalを使ったグラフィックスの本である。この中にタートル・グラフィックスの例題が沢山あるので今回はこれらをPythonのタートル・グラフィックスで書いてみた。なるべく忠実に例題をなぞるようにした。
例題1:kame
#coding: utf-8
import turtle
def sugata( center, size):
for i in range(6):
painter = center.clone()
painter.fd(size)
painter.rt(120)
painter.fd(size)
center.rt(60)
def kame( position, size):
sugata( position, size)
if __name__ == '__main__':
turtle.clearscreen()
position = turtle.Turtle()
position.ht()
position.lt(90)
kame( position, 200)
多少気になったのは以下の部分である:
painter = center.clone()Pascalでは単なる代入文でpainter=centerとなっている。Pythonでは代入文によるオブジェクトの代入はできない。copyモジュールのcopyメソッドを使ってみたが描画の一部が消えてしまう。deepcopyではTkinterのエラーがでる。Pythonのタートル・グラフィックのドキュメントにあったclone()で期待した通りの描画が得られた。clone()とcopyメソッドの相違は不明。
【結果の描画】
なお描画ではカメ印(?)は隠してある。
もう一つ実例を考える。
【実例2】
TO sugata nagasa
REPEAT 2 [
FORWARD nagasa
LEFT 120 ]
HOME
END
TO kame nagasa
kakudo = 0
REPEAT 6 [
sugata nagasa
kakudo = kakudo + 60
RIGHT kakudo ]
END
PENCOLOR “black”
HOME
kame 200
日本語化すると:
やるべきこと sugata nagasa
繰り返し 2 [
前へ nagasa
左へ120 ]
定位置へ
記述終わり
やるべきこと kame nagasa
kakudo = 0
繰り返し 6 [
sugata nagasa ;やるべきことsugata実行
kakudo = kakudo + 60
右へ kakudo ]
記述終わり
ペンの色 “black”
定位置へ
kame 200 ;やるべきことkame実行
HOMEは「定位置へ」とした。インデントを使うと少し見やすくなる。
【結果の描画】
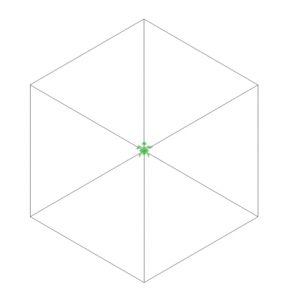
こんなプログラムを考える:
TO draw length n
IF n = 0 [
STOP ]
angle = 60
FORWARD length * n
LEFT angle
draw length n-1
RIGHT 2 * angle
draw length n-1
LEFT angle
BACK length * n
END
PENCOLOR “black”
draw 20 5
HOME
PENCOLOR “red”
draw 22 5
大文字のみの単語はLibreLogoの既約語である。この既約語を日本語で表現する。
例えば以下の様にしてみた:
やるべきこと draw length n
もしも n = 0 [
実行終了 ]
angle = 60
前へ length * n
左へ angle
draw length n-1
右へ 2 * angle
draw length n-1
左へ angle
後へ length * n
記述終わり
ペンの色 “black”
draw 20 5 ;やるべきことdrawの実行
定位置へ
ペンの色 “red”
draw 22 5 ;やるべきことdrawの実行
TO(やるべきこと)、END(記述終わり)あたりが難しい。プログラミングで使われている英単語は短くそれ自身では符牒のようなものだ。日本語化ではそれに捉われず多少冗長でも機能が明確になるような語句にするとよいと思った。
LibreOfficeのWriter(文書処理)は一つの機能としてタートル・グラフィックスのためのプログラミング環境を提供している。それがLibreLogoである。文書処理の中にプログラミング環境を提供するという発想が面白い。コンピュータ・プログラミングの敷居を低めることができるかもしれない。LOGOに似た言語が使える。LibreLogoの詳細はここにある。
早速使ってみる。再帰関数が動くか確かめた。以下が使った再帰関数の一例である。
【再帰関数】
TO draw length n
IF n = 0 [ STOP ]
angle = 60
FORWARD length * n
LEFT angle
draw length n-1
RIGHT 2 * angle
draw length n-1
LEFT angle
BACK length * n
END
draw 20 5
TO draw length nからENDまでが再帰関数の定義である。大文字ばかりの単語はLibreLogoの既約語である。これには日本語が使える。
【実行結果】
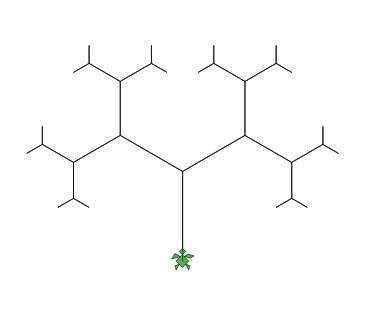
LibreLogoで再帰処理ができることが解った。