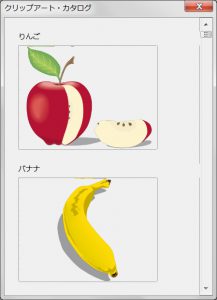
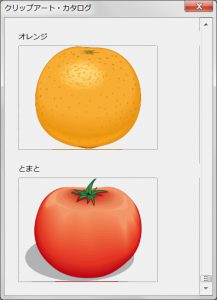
Pythonでマクロ:チェックボックス再論ではダイアログ上にチェックボックスを自動的に作成する問題を考えた。チェックボックスが多くなるとチェックボックスがダイアログ画面に納まらなくなる。(垂直)スクロールバーの出番である。
スクロールバーのモデルの詳細はここにある。
スクロールバーのツマミを動かすと
イヴェントが発生するがこのイヴェントの監視とイヴェント処理メッソド(adjustmentValueChanged)の詳細はここにある。
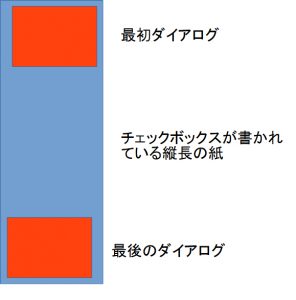
チェックボックスは上図のようにダイアログ画面に納まらない縦長の紙に書かれていると想像してみる。このイヴェント処理メッソドではスクロールバーのツマミの位置の値(ScrollValue)を使ってこの縦長の紙の方を動かして紙のどの部分をダイアログ画面で見せるかを計算し個々のチェックボックスのダイアログ画面上の座標を変えてやる。
実行例の画像
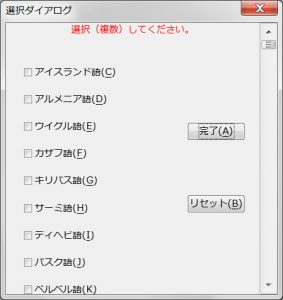 最初のダイアログ画面
最初のダイアログ画面
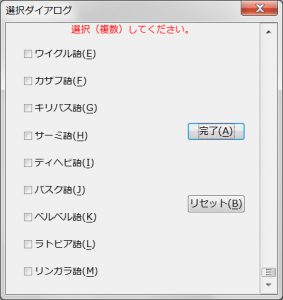 最後の外アログ画面
最後の外アログ画面
スクロール・ツマミの動きに対してダイアログ画面をスムーズに変化させるにはスクロール属性LiveScrollをtrueにしておくとよい。
最後にマクロ本体を載せておく:
#coding: utf-8
import uno
import screen_io as ui
import unohelper
from com.sun.star.awt import XActionListener
from com.sun.star.awt import XAdjustmentListener
#「スクロールバー」の処理
class MyAdjustmentListener(unohelper.Base, XAdjustmentListener):
def __init__(self, dlgHgt, ckbxsHgt, ckbxs):
self.ckbxs = ckbxs
self.scrollVMax=100
self.dlgHgt=dlgHgt
self.ckbxsHgt=ckbxsHgt
self.ckbxPositionY0 = []
for ckbx in ckbxs:
print(ckbx.PositionY)
self.ckbxPositionY0.append(ckbx.PositionY)
def adjustmentValueChanged(self, event):
ratio = event.Value/self.scrollVMax
print(ratio)
for i,ckbx in enumerate(self.ckbxs):
ckbx.PositionY = self.ckbxPositionY0[i]-(self.ckbxsHgt - self.dlgHgt)*ratio
print( i, self.ckbxPositionY0[i], ckbx.PositionY)
#print(event.Type)
#print(event.Value)
#「完了」ボタンの処理
class FinishedListener(unohelper.Base, XActionListener):
def __init__(self, ckbxs, sheet):
self.ckbxs = ckbxs
self.sheet=sheet
def actionPerformed(self, evnt):
for i,ckbx in enumerate(self.ckbxs):
if(ckbx.State):
self.sheet.getCellByPosition(1, i+1 ).String = '○'
#ui.Print(ckbx.State)
#「リセット」ボタンの処理
class ResetListener(unohelper.Base, XActionListener):
def __init__(self, ckbxs):
self.ckbxs = ckbxs
def actionPerformed(self, evnt):
for ckbx in self.ckbxs:
ckbx.State=0
def python_macro_scbar(*arg):
#
#シート
doc = XSCRIPTCONTEXT.getDocument()
sheet = doc.Sheets[0]
#データのある行数を調べる
sRange = sheet.getCellRangeByName("A1")
sCursor=sheet.createCursorByRange(sRange)
sCursor.collapseToCurrentRegion()
MaxDataRow = sCursor.Rows.Count-1
ui.Print(MaxDataRow)
items=[]
for i in range(MaxDataRow):
item = sheet.getCellByPosition(0, i+1 ).String
#ui.Print(item)
items.append(item)
#
#ダイアログ
ctx = XSCRIPTCONTEXT.getComponentContext()
smgr = ctx.getServiceManager()
dialogM = smgr.createInstance('com.sun.star.awt.UnoControlDialogModel')
# Size of DialogM
dlgWth = 150
dlgHgt = 150
dialogM.Width = dlgWth
dialogM.Height = dlgHgt
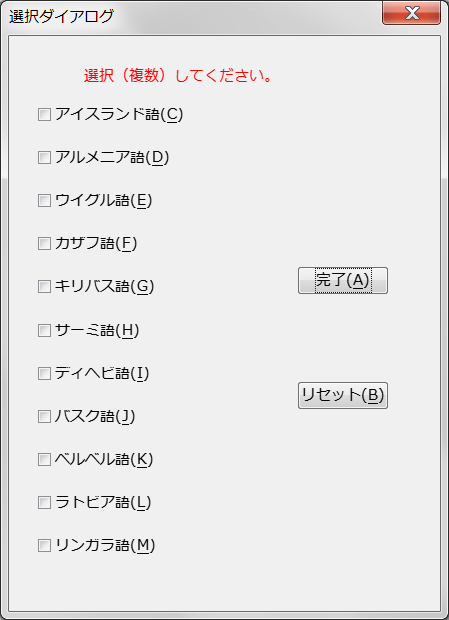
dialogM.Title = "選択ダイアログ"
#
#コントロールの作成・登録
#ラベル
lab1 = dialogM.createInstance('com.sun.star.awt.UnoControlFixedTextModel')
tabIndex = 0
lab1.Name = 'FixedLabel'
lab1.TabIndex = tabIndex
lab1.PositionX =0
lab1.PositionY =0
lab1.Width = dlgWth - 10
lab1.Height = 10
lab1.Label = "選択(複数)してください。"
lab1.Align = 1 # 0 : Left / 1 : Center / 2 : Right
lab1.Border = 0
lab1.TextColor = 0xff0000
lab1.Enabled = 1
dialogM.insertByName('FixedLabel', lab1)
#スクロールバー
scb1 = dialogM.createInstance('com.sun.star.awt.UnoControlScrollBarModel')
tabIndex += 1
scrollVMin=0
scrollVMax=100
scb1.Name = 'ScrollBar'
scb1.TabIndex = tabIndex
scb1.PositionX = dlgWth-10
scb1.PositionY = 0
scb1.Width = 10
scb1.Height = dlgHgt
scb1.Orientation=1
scb1.ScrollValueMin = scrollVMin
scb1.ScrollValueMax = scrollVMax
scb1.LiveScroll= 1
dialogM.insertByName('ScrollBar', scb1)
#ボタン
btn1 = dialogM.createInstance('com.sun.star.awt.UnoControlButtonModel')
tabIndex += 1
btn1.Name = 'OkBtn'
btn1.TabIndex = tabIndex
btn1.PositionX = dlgWth-50
btn1.PositionY = dlgHgt/2 - 20
btn1.Width = 32
btn1.Height = 10
btn1.Label = '完了'
btn1.PushButtonType = 0 # 1 : OK
dialogM.insertByName('OkBtn', btn1)
#
btn2 = dialogM.createInstance('com.sun.star.awt.UnoControlButtonModel')
tabIndex += 1
btn2.Name = 'ResetBtn'
btn2.TabIndex = tabIndex
btn2.PositionX = dlgWth-50
btn2.PositionY = dlgHgt/2 + 20
btn2.Width = 32
btn2.Height = 10
btn2.Label = 'リセット'
btn2.PushButtonType = 0 # 1 : OK
dialogM.insertByName('ResetBtn', btn2)
#チェックボックス
ckbxs=[]
for i in range(MaxDataRow):
ckbx = dialogM.createInstance('com.sun.star.awt.UnoControlCheckBoxModel')
tabIndex += 1
ckbxsHgt = 15+15*i+10
ckbx.Name = items[i]
ckbx.TabIndex = tabIndex
ckbx.PositionX = 10
ckbx.PositionY = ckbxsHgt
ckbx.Width = 100
ckbx.Height = 15
ckbx.Label = items[i]
# Dialog Modelの仕様に CheckBox Button1 の仕様を設定
dialogM.insertByName(items[i], ckbx)
ckbxs.append(ckbx)
#最終的なチェックボックス表の高さ
ckbxsHgt=ckbxsHgt+15
# Create the dialog and set the model
#ダイアログの生成とモデルの登録
dialog = smgr.createInstance('com.sun.star.awt.UnoControlDialog')
dialog.setModel(dialogM)
#コントロールの登録
cmdBtn1 = dialog.getControl('OkBtn')
cmdBtn2 = dialog.getControl('ResetBtn')
cmdScb1 = dialog.getControl('ScrollBar')
#エヴェント監視(ボタンが押されたとき)
btn1_listener = FinishedListener(ckbxs, sheet)
cmdBtn1.addActionListener(btn1_listener)
btn2_listener = ResetListener(ckbxs)
cmdBtn2.addActionListener(btn2_listener)
#エヴェント監視(スクロールバー)
scb1_listener = MyAdjustmentListener(dlgHgt, ckbxsHgt, ckbxs)
cmdScb1.addAdjustmentListener(scb1_listener)
#
#窓の生成そしてこの窓をダイアログ画面として使う
window = smgr.createInstance('com.sun.star.awt.Toolkit')
dialog.createPeer(window,None) # None : OK / none : NG
#
dialog.execute()
dialog.dispose()


{kind=link}
{kind=link}
{kind=link}
{kind=link}