
藤沢周平は好きな作家の一人である。以前のこのブログで話題にしたことがある。
文庫本のかたちで全作品を持っている。どの作品がどのタイトルの文庫本に収録されているかを検索できるデータベースを作ってみた。
一例を示す:
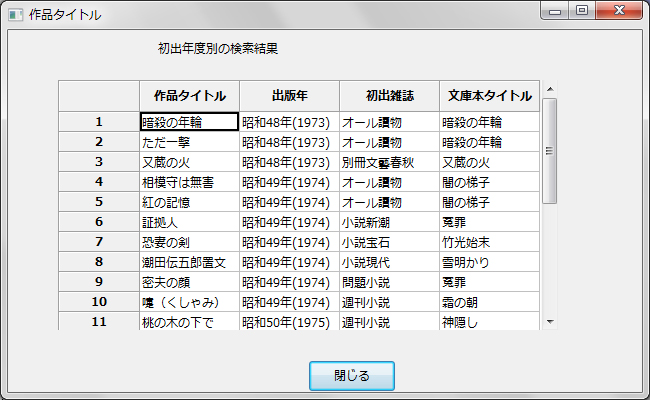
wxPythonにはデータベースの結果表示に便利なgridクラスがあり表になったデータを適切に表示できる。
藤沢周平は好きな作家の一人である。以前のこのブログで話題にしたことがある。
文庫本のかたちで全作品を持っている。どの作品がどのタイトルの文庫本に収録されているかを検索できるデータベースを作ってみた。
一例を示す:
wxPythonにはデータベースの結果表示に便利なgridクラスがあり表になったデータを適切に表示できる。
マルチスレッドの一般論はここにある。プログラムで重たい処理の部分を干渉なしにバッチ処理的にやる部分を一つのスレッドと他の部分と独立に実行させる。こんなイメージがスレッドである。
Python上でスレッドを使った一例を示す:
import threading
a_final = 0
def count():
global a_final
for i in range(10000000):
a = i+1
a_final = a
print('end_count')
return
def main():
t = threading.Thread(target=count)
t.daemon = True
t.start()
t.join()
print(a_final)
print('end_main')
if __name__ == '__main__':
main()
関数mainの中で関数countをスレッドとして走らせる。メソッドJoin()はスレッドとそのスレッドを走らせた関数(今の場合はmain)が同時に終了するように同期をとるメソッドである。
これのGUI版は以下のようになる:
import tkinter as tk
from tkinter import ttk
import threading
a_final = 0
root = tk.Tk()
label = tk.Label(text='vinoth')
label.pack()
def fix():
t = threading.Thread(target=count)
t.daemon = True
t.start()
t.join()
label['text'] = a_final
return
def count():
global a_final
for i in range(100000000):
a = i+1
a_final = a
button = tk.Button(text='sub', command=fix)
button.pack()
dropdown = ttk.Combobox()
dropdown.pack()
root.mainloop()
こんな感じになる。
Pythonで書いたプログラムを高速に実行する仕掛けを調べていたら面白い記事に出会った。そこで公開されているプログラムを紹介しつつ、僕のところで実行した結果を示す。
基本になるプログラム(killing_time.py)は以下のようなものである:
import time
# 単に時間がかかるだけの処理
def killing_time(number):
return_list = []
for i in range(1, number + 1):
if number % i == 1:
if i <= 9999:
return_list.append(i)
return return_list
start = time.time()
num_list = [25000000, 20000000, 20076000, 14500000]
for n in num_list:
result_list = list(killing_time(n))
stop = time.time()
print('%.3f seconds' % (stop - start))このプログラムを実行してみた。使った環境はwindows 7でPyhtonのヴァージョンは3.7.6である。
実行結果は
5.763 seconds
このプログラムをスレッド化したもの(killing_time_thread.py)がある。プログラムはここ。
実行結果は
5.779 seconds
となり、Pythonスレッドは速度向上には繋がらない。
またこのプログラムを並列処理させるようにしてみる(killing_time_concurrent.py)。プログラムはここ(CPUの最大数は4)。
実行結果は
3.703 seconds
となり、実行速度は若干改良される。
ここまでがオリジナルの記事を追試したもので記事の結果をほぼ再現した。
次にこの三つのプログラムをPythonコンパイラ(pypy)で実行させてみた結果を述べる。pypyのヴァージョンは
Python 3.6.9 (2ad108f17bdb, Apr 07 2020, 03:05:35)
[PyPy 7.3.1 with MSC v.1912 32 bit]
実行結果は
killing_time.py -------------> 0.713 seconds
killing_time_thread.py) -----> 0.462 seconds
killing_time_concurrent.py --> 1.049 seconds
となった。なにも手を入れないプログラムでもコンパイラで実行するとかなりの実行速度向上ができることが分る。
pypyはnumpyモジュールなどの拡張モジュールとの相性が悪い。しかしネイティヴPythonのみを使ったプログラムは高速に実行できる。
最近亡くなったコンウェイ(John Horton Conway)が提唱したライフゲームを高速に実行するPythonプログラムの話である。
この「ゲーム」はセル・オートマトンの一種で二次元格子にオートマトンを置きその時間変化を追い、描画する。各格子のセルオートマトンの状態は生(1)か死(0)の二状態をとる(ライフゲームの由来?)。各格子の状態変化は当該のセルの状態と周囲のセルの状態によって決まる。ここの状態変化の計算は超並列に行うことができる。
計算式は極めて簡単でPythonでも実行時間は掛からないが、格子の数が増えるとセルの状態を描画する時間がバカにならない。そこで描画をヴィデオデータにしてしまってそのデータを画面表示する。こんなことを考えて調べていたら、同じようなことを考えているヒトがいてプログラムを公開している。かなり高速なシミュレーションができる。使ったプログラムはここ。セルの数は300X300=9万である。
実行結果

pythonにはTurtleグラフィックスが同梱されている。このグラフィックスの実行画面をTKinterのカンヴァスに表示する方法がある。「開始」ボタンを押すと実行が始まるといった感じである。プログラムはここ。
実行画面

Pythonに同梱されているTKinterはあまり苦労しないでGUIのPythonアプリケーションが作れる詳しい説明はここ)。アプリケーションで静止画像を見せることなどは追加のモジュール無しでできる。そこでTKinterアプリケーションでヴィデオを見せることができるか調べてみた。
映像は毎秒60コマで更新されるのでこの頻度で映像を取り込み表示すればよい。取り込んだ映像はlabelウィジェットに表示する。プログラムはここ。
映像によってフレーム・レイト(毎秒のコマ数)が異なるのでそれを反映した頻度で画面を更新することが必要である。また大きな画面サイズの動画は再生速度が足らなくなる問題がある。プログラムはここ。
実行例

この二例でみるようにTKinterは充分でヴィデオ・データにも対応できる。
Pythonを高速にする仕掛けの一つに’NUMBA’というモジュールがある。これは配列の計算のためのもモジュールNUMPYで定義された配列に計算を高速にする。NUMPY自体も配列の計算(例えば二つの配列の積)ができるが、配列の計算はもっと沢山ある。そうのような計算をPythonの演算式を使ってやるととてつもなく時間がかかる。そのような計算部分(関数として定義する)をNUMBAで高速にできる。例を示す:
#coding: utf-8
from numba import jit
from numpy import arange
import time
#関数の引数にNUMPY moduleで定義される配列があるとNUMBA
#によってその関数はコンパイルされる。
#デコレータ@jitはNUMBAを適用するか選択する
@jit
def sum2d(arr):
M, N = arr.shape
result = 0.0
for i in range(M):
for j in range(N):
result += arr[i, j]
return result
start = time.time()
a = arange(100000000).reshape(10000, 10000)
print(sum2d(a))
elapsed_time = time.time() - start
print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")
結果を示す:
30倍もの実行速度がえられる。Pythonコンパイラとしては以前に紹介した’pypy’もあるがNumpyを使っている場合はこのNumbaが便利かもしれない。
久ぶりにPythonの話題である。
インタプリタであるPythonは実行速度が遅い。この遅い原因を回避するためにPython言語で作ったプログラムをコンパイルして実行するPypyというコンパイラがある。どの位の性能があるか試してみた。環境はOSはwindows7で、使ったPythonおよびPypyのヴァージョンは
>>python -V
Python 3.7.6
>>pypy3 -V
Python 3.6.9 (2ad108f17bdb, Apr 07 2020, 03:05:35)
[PyPy 7.3.1 with MSC v.1912 32 bit]
例1:単純な四則計算
import time
start = time.time()
for i in range(100000000): # 10^8
1 + 1
1 - 1
1 * 1
1 // 1
process_time = time.time() - start
print(process_time)
結果は
Python3.7 4159ms
Pypy 95ms
となり、約40倍の速度向上が見られた。
例2:配列
import time
start = time.time()
A = [i for i in range(10000000)] # 10^7
for i in range(10000000):
A[i] = 0
process_time = time.time() - start
print(process_time)
結果は
Python3.7 1844ms
Pypy 70ms
となり、約30倍の速度向上が見られた。
ヴォロノイ(Voronoi)図をPythonを使って描く。
じつはパッケージSciPyにヴォロノイ図を描くモジュールがある。今回はそれを使ってみた。出来上がった図の一例を示す。
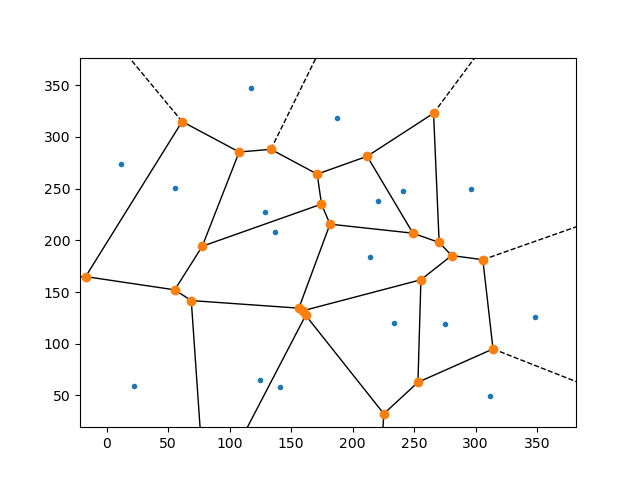
このパッケージは日本語を含むファイルPath名のファイルを作成できない。これが苦労したところ。
年末やら新年にかけて、文献「TkinterでGUIを作ろう」の大幅な改訂を行った。
改訂版はここになる。