LibreOfficeのマクロをpythonで作ってみた。
標題のように「誕生日から今日まで日数を知る」ためのマクロである。表の誕生日データ(年、月、日)を使い目的の日数を表に記入する。
【例】1950/12/05生まれの人は今日(2021/04/29)までで25713日経過している。
暦計算ではユリウス日(Julian Day)が使われる。これは紀元前4713年1月1日からの連続した通し番号の日数である。この連続した日付けを使うと誕生日から今日までに経過した日数を知ることができる。Pythonではdatetimeモジュールでこれらの機能を提供している。これをマクロで使う。
プログラムの全体は以下のようになる:
#coding: utf-8
import uno
import screen_io as ui
import time
from datetime import date
class Birthday:
def __init__(self, mydate):
self.year= mydate[0]
self.month=mydate[1]
self.day= mydate[2]
def get_date(self):
return date(self.year, self.month, self.day)
def get_days(self):
today = date.today()
my_birthday=date(self.year, self.month, self.day)
time_to_birthday=abs(today-my_birthday)
return time_to_birthday.days
def get_years_days(self):
my_birthday=date(self.year, self.month, self.day)
today = date.today()
today_year=today.year
my_last_birthday=date(today.year-1,self.month, self.day)
lastday=date(today_year-1,12,31)
my_birthday_thisyear=date(today.year, self.month, self.day)
daydiff_today=abs(today-lastday)
daydiff_birthday=abs(my_birthday_thisyear-lastday)
if daydiff_today > daydiff_birthday:
yearspan=today.year - my_birthday.year
dayspan=abs(today-my_birthday_thisyear)
else:
yearspan=today.year - my_birthday.year-1
dayspan=abs(today - my_last_birthday)
return (yearspan, dayspan.days)
def elapsed_days_macro():
doc = XSCRIPTCONTEXT.getDocument()
sheet = doc.Sheets[0]
today=date.today()
msg = "今日は"+str(today)+"です。"
ui.Print( msg)
#データのある行数を調べる
sRange = sheet.getCellRangeByName("A1")
sCursor=sheet.createCursorByRange(sRange)
sCursor.collapseToCurrentRegion()
MaxDataRow = sCursor.Rows.Count-1
for i in range(MaxDataRow):
year = int(sheet.getCellByPosition(0, i+1 ).Value)
month =int(sheet.getCellByPosition(1, i+1 ).Value)
day = int(sheet.getCellByPosition(2, i+1 ).Value)
mydate=(year, month, day)
my_birthday=Birthday(mydate)
sheet.getCellByPosition(3,i+1).Value=my_birthday.get_days()
sheet.getCellByPosition(4,i+1).Value=my_birthday.get_years_days()[0]
sheet.getCellByPosition(5,i+1).Value=my_birthday.get_years_days()[1]
return
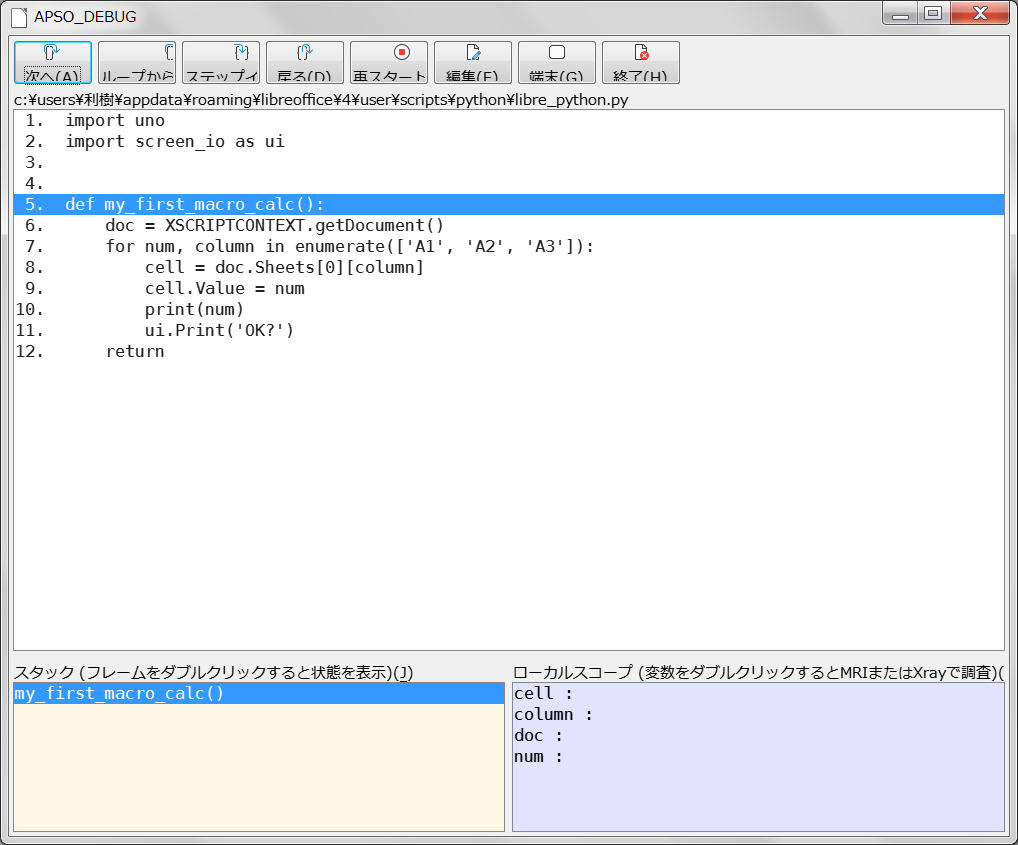
LIbreOfficeのPythonマクロで使える関数・定数などの情報は「マクロの森」が詳しい。また、ASOPのデバッガやコンソールはプログラミングに結構役に立つことが分った、